python数据分析之桑吉图
近期在整理公司的数据,因为使用tableau做出桑吉图太过复杂,所以使用python尝试了一下。
先来看一下桑基图是什么
桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图。它是一种特定类型的流程图,图中延伸的分支的宽度对应数据流量的大小,通常应用于能源、材料成分、金融等数据的可视化分析。因1898年Matthew Henry Phineas Riall Sankey绘制的”蒸汽机的能源效率图”而闻名,此后便以其名字命名为”桑基图”。
特点:
- 属于流程图的一种,核心在于展示数据的流转
- 主要由节点、边和流量三要素构成,边越宽代表流量越大
- 遵循守恒定律,无论怎么流动,开端和末端数据总是一致的
Python绘制桑基图
在绘制桑基图前,我们回顾一下桑基图组成要素的重点——节点、边和流量。
任何桑基图,无论展现形式如何夸张,色彩如何艳丽,动效如何炫酷,本质都逃不出上述3点。
只要我们定义好上述3个要素,Python的pyecharts库能够轻松实现桑基图的绘制。
首先,我们应该导入哪些库
1 | import pandas as pd |
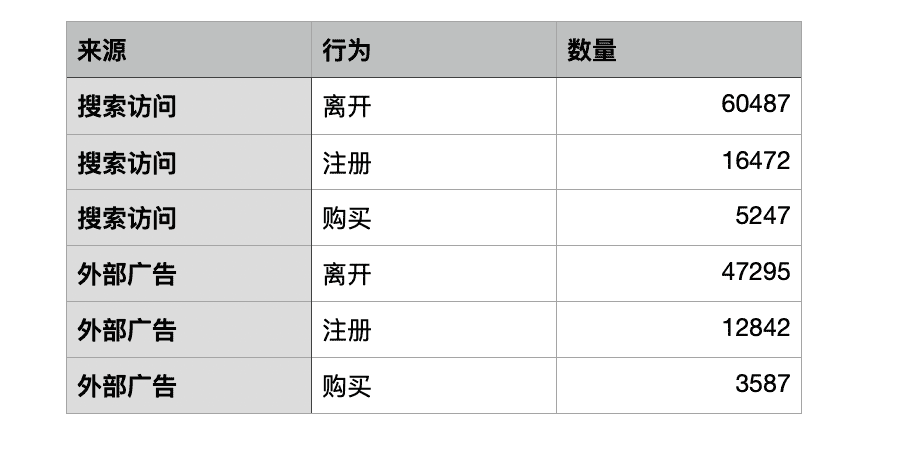
这里用常用的用户转化数据为例:
首先,处理一下数据
这里我们会先把数据预处理一下,保存为表格csv
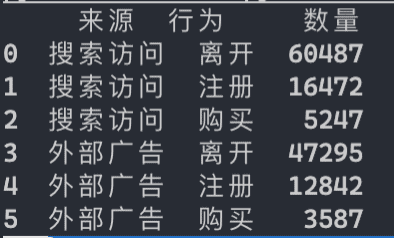
Python中我们借助pandas把csv读取为DateFrame:
1 | df = pd.read_csv(filepath) |
print看一下是否正确
进一步处理
首先先处理节点,这一步需要把所有涉及到的节点去重规整在一起。也就是要把来源一列的“搜索访问”、“外部广告”和行为一列的“离开”、“注册”、“购买”以列表内嵌套字典的形式去重汇总:
1 | nodes = [] |


喜欢这篇文章的人也看了




评论
隐私政策






